Text Analysis Project
Comparing approaches to analyzing news articles on Michigan data centers
The Project Overview
In our final collaborative project, the class compared two approaches of doing text analysis, one powered by AI, and one that's not:
- AI-Assisted Topic Modeling: Using ProQuest TDM's built-in 'Visualization' service
- Python-Based LDA: Developing a Latent Dirichlet Allocation workflow in Jupyter notebook
The Two Approaches
ProQuest TDM Visualization Service
An AI-assisted topic modeling service that provides a user-friendly interface for text analysis. The service handles preprocessing and topic extraction automatically and in minutes.
Pros:
- Easy to use, no coding required
- Quick results
- Handles preprocessing automatically
Cons:
- Less control/understanding over how data was processed
- Some topics had random or unrelated words, and words that overlapped between sections.
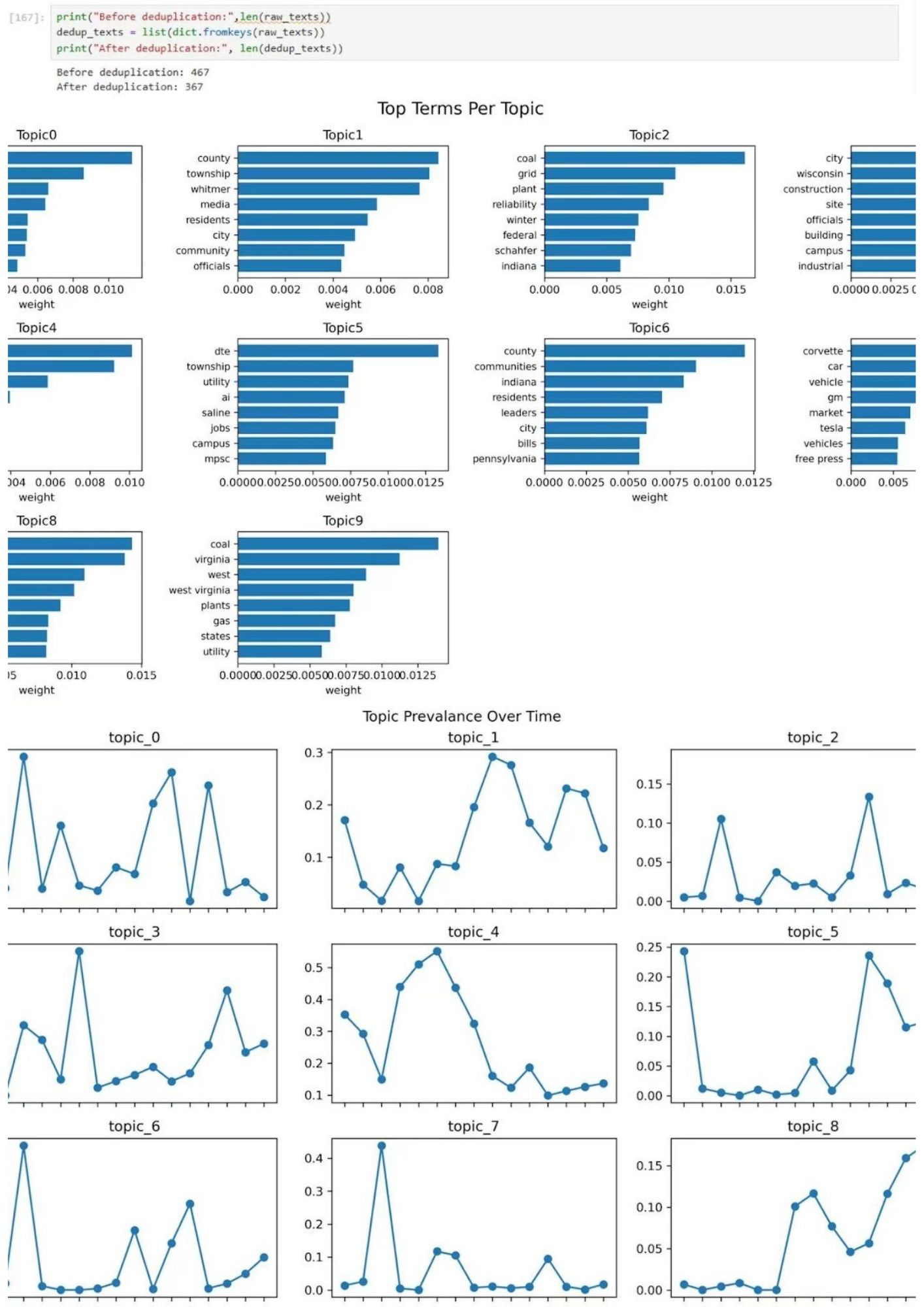
Python LDA Workflow
A custom Jupyter notebook workflow where students wrote Python code to implement Latent Dirichlet Allocation from scratch.
Pros:
- Full control over preprocessing, including ability to remove duplicate words
- Transparent methodology
- Customizable parameters
Considerations:
- Requires programming knowledge
- More time investment
Topic Modeling Explained
What is Topic Modeling?
Topic modeling is an unsupervised machine learning technique that automatically identifies themes or "topics" within a collection of documents. It works by finding groups of words that frequently appear together, assuming these represent coherent topics. The dataset we analyzed covered nearly fifteen months of relevant news articles on data centers in Michigan. There were nearly 500 articles in total.
Key Findings
Why Transparency Matters
By comparing these two approaches, we discovered how preprocessing decisions and parameter choices shape topic modeling outcomes. The same data can reveal different "topics" depending on how it's processed and analyzed.
What We Learned
- Preprocessing Matters: How text is cleaned, tokenized, and filtered significantly affects results
- Parameter Sensitivity: The number of topics, iteration count, and other parameters influence outcomes
- Reproducibility: Transparent code-based approaches enable others to verify and build upon work
Implications for Research
This project demonstrates that AI tools are not neutral—they embed assumptions and choices that shape what we learn. For researchers, this means:
- Understanding how tools work is essential for critical interpretation
- Documentation and transparency support scholarly rigor
- Comparing methods reveals the influence of methodological choices